Learning Various Languages
How do languages compare in terms of complexity? How does one understand language? These are some important questions which not only remain to be answered, but are elusive to even unify.
Recurrent Neural Networks may be just such a tool. In this work, I compare 24 alphabetic languages (languages which are written in terms of a small set of symbols, rather than a symbol for each word) through neural networks. A recurrent network is trained to predict the next character, and it gets so good at it that it begins to model words, sentences, and concepts of a language without being given any high-level supervision.
I can then compare the success of a given network across these different languages. Here’s the graph, ordered from ‘simplest’ to ‘most complicated’.
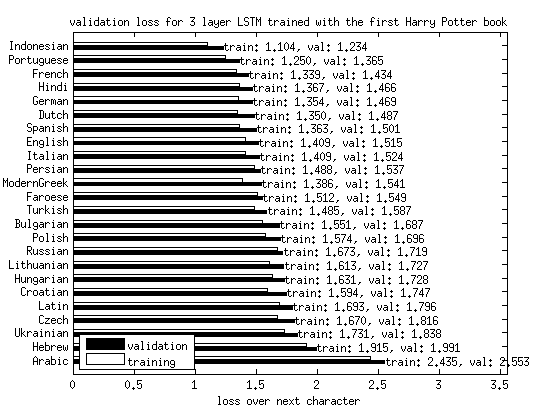
What can we conclude from this? Well, it looks like getting the next character right in Indonesian and Portuguese is easier than other languages, especially Arabic. That’s an impressive conclusion, given that I have not manually had to look at how those languages work at all. Slavonic languages are harder than Germanic and Celtic, as expected given their declinations and gender modifiers.